publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
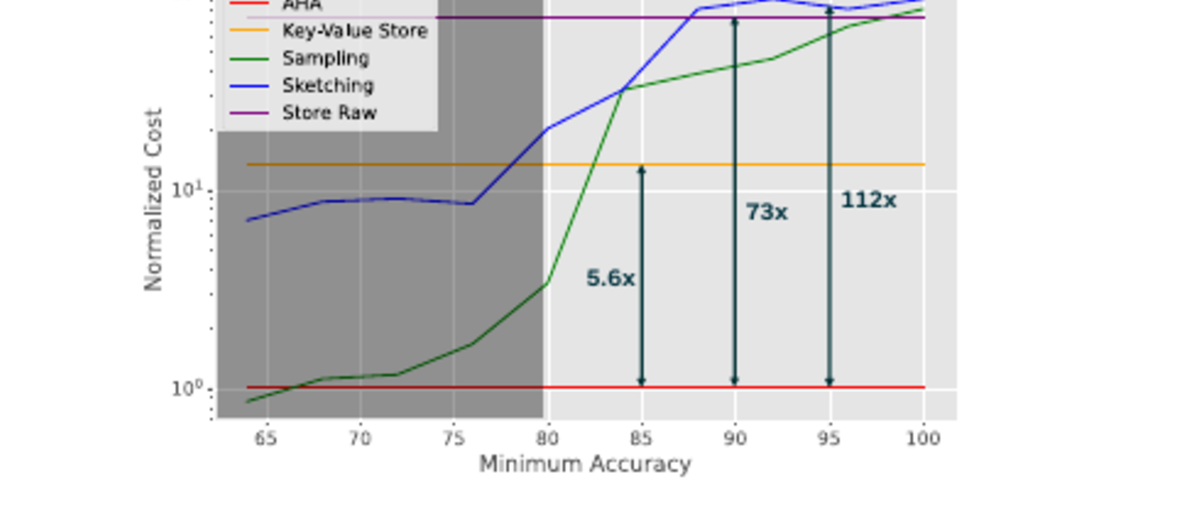 AHA: Scalable Alternative History Analysis for Operational Timeseries ApplicationsKamarthi, Harshavardhan, Shah, Harshil, Milner, Henry, Sinha, Sayan, Li, Yan, Prakash, B Aditya, and Sekar, VyasTo appear in KDD 2026
AHA: Scalable Alternative History Analysis for Operational Timeseries ApplicationsKamarthi, Harshavardhan, Shah, Harshil, Milner, Henry, Sinha, Sayan, Li, Yan, Prakash, B Aditya, and Sekar, VyasTo appear in KDD 2026Many operational systems collect high-dimensional timeseries data about users or systems on key performance metrics. Over such historical data, operators and data analysts often need to run retrospective analysis, such as analyzing anomaly detection algorithms, experimenting with different alert configurations, and evaluating new algorithms. We refer to this class of workloads as alternative history analysis for operational datasets. We design and implement AHA, a system that provides cost efficiency and fidelity for high-dimensional data by leveraging decomposable statistics, sparsity in active subpopulations, and efficient aggregation structure in modern analytics databases. Using multiple real-world datasets and production-pipeline case studies at a large video analytics company, AHA provides 100% accuracy for a broad range of downstream tasks and up to 85x lower total cost of ownership compared to conventional methods.
@article{kamarthi2026aha, abbr = {aha26}, title = {AHA: Scalable Alternative History Analysis for Operational Timeseries Applications}, author = {Kamarthi, Harshavardhan and Shah, Harshil and Milner, Henry and Sinha, Sayan and Li, Yan and Prakash, B Aditya and Sekar, Vyas}, journal = {To appear in KDD}, year = {2026}, selected = {true}, pdf = {https://arxiv.org/abs/2601.04432}, bibtex_show = {true} } -
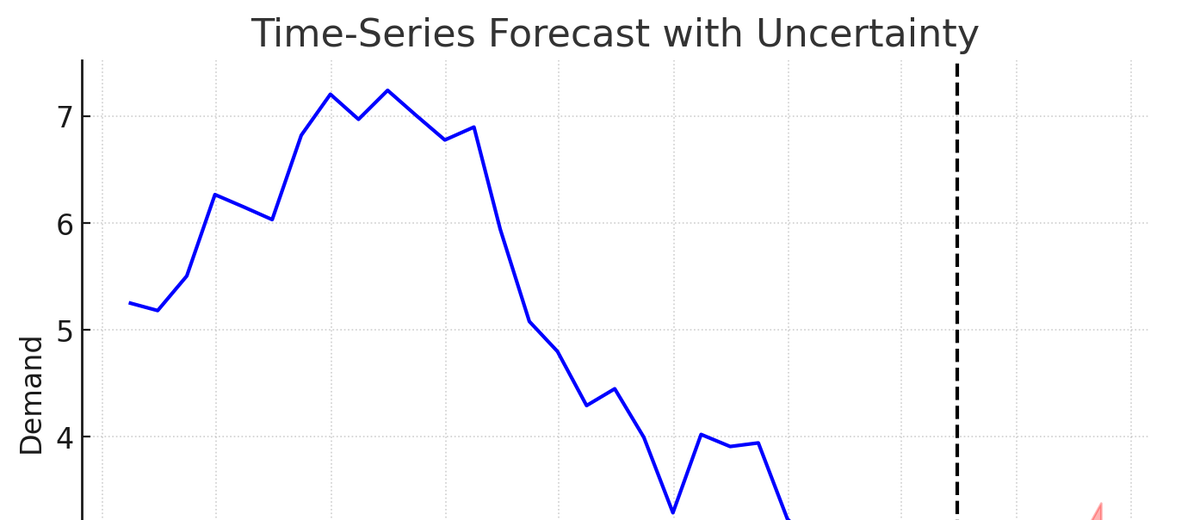 Hierarchical Industrial Demand Forecasting with Temporal and Uncertainty ExplanationsKamarthi, Harshavardhan, Xu, Shangqing, Tong, Xinjie, Zhou, Xingyu, Peters, James, Czyzyk, Joseph, and Prakash, B AdityaICDE 2026
Hierarchical Industrial Demand Forecasting with Temporal and Uncertainty ExplanationsKamarthi, Harshavardhan, Xu, Shangqing, Tong, Xinjie, Zhou, Xingyu, Peters, James, Czyzyk, Joseph, and Prakash, B AdityaICDE 2026Hierarchical time-series forecasting is essential for demand prediction across industries, but the interpretability of such forecasts remains largely unexplored. We introduce an interpretability method for large hierarchical probabilistic time-series forecasting that adapts generic interpretability techniques while addressing hierarchy and uncertainty. The approach explains the significance of time series and external variables at specific time points, the impact of variables on forecast uncertainty, and forecast changes caused by training-data modifications. Experiments on semi-synthetic datasets based on industrial demand scenarios and real-world case studies demonstrate that the method explains state-of-the-art industrial forecasting models with significantly higher explainability accuracy.
@article{kamarthi2026hidex, abbr = {hidex26}, title = {Hierarchical Industrial Demand Forecasting with Temporal and Uncertainty Explanations}, author = {Kamarthi, Harshavardhan and Xu, Shangqing and Tong, Xinjie and Zhou, Xingyu and Peters, James and Czyzyk, Joseph and Prakash, B Aditya}, journal = {ICDE}, year = {2026}, selected = {true}, pdf = {https://arxiv.org/abs/2603.06555}, bibtex_show = {true} }
2025
-
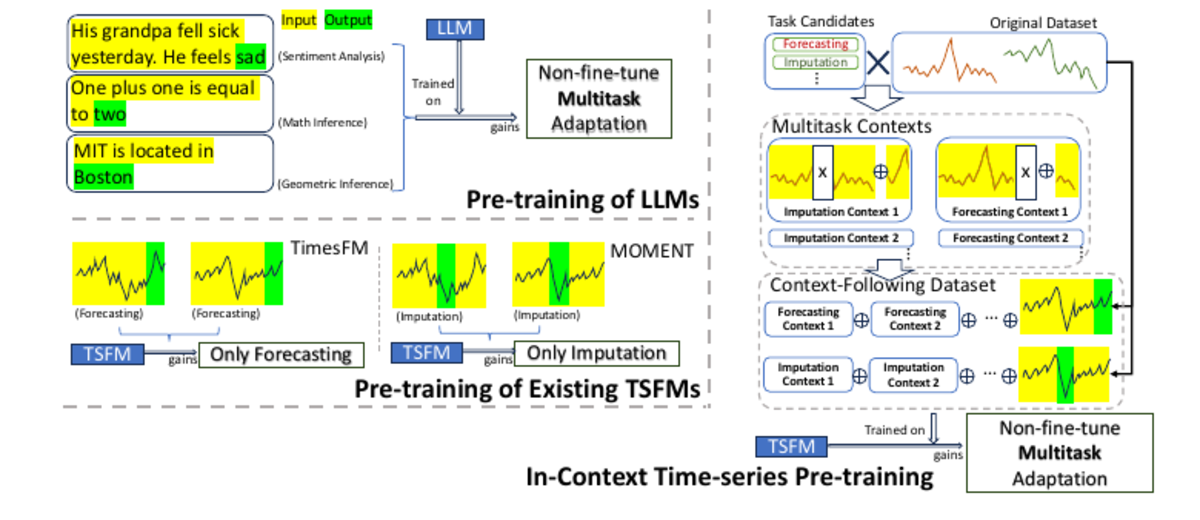 In-context Pre-trained Time-Series Foundation Models adapt to Unseen TasksIn CIKM 2025
In-context Pre-trained Time-Series Foundation Models adapt to Unseen TasksIn CIKM 2025Time-series foundation models have demonstrated strong generalization across diverse datasets and tasks, but existing models are usually pre-trained for specific tasks and often struggle to generalize to unseen tasks without fine-tuning. We propose In-Context Time-series Pre-training (ICTP), which restructures pre-training data to equip a backbone time-series foundation model with in-context learning capabilities. ICTP enables test-time adaptation to unseen tasks from input-output relationships provided in context and improves state-of-the-art time-series foundation models by approximately 11.4% on unseen tasks without fine-tuning.
@inproceedings{xu2025ictp, abbr = {ictp25}, title = {In-context Pre-trained Time-Series Foundation Models adapt to Unseen Tasks}, author = {Xu, Shangqing and Kamarthi, Harshavardhan and Liu, Haoxin and Prakash, B Aditya}, booktitle = {CIKM}, pages = {5386--5390}, year = {2025}, selected = {true}, pdf = {https://arxiv.org/abs/2602.20307}, bibtex_show = {true} } -
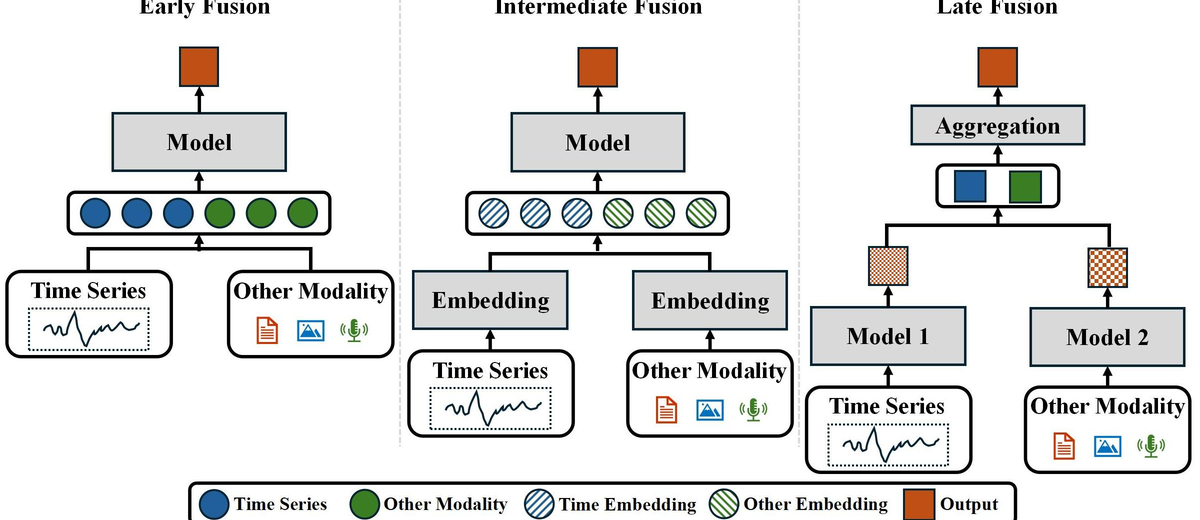 How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and OutlookLiu, Haoxin, Kamarthi, Harshavardhan, Zhao, Zhiyuan, Xu, Shangqing, Wang, Shiyu, Wen, Qingsong, Hartvigsen, Tom, Wang, Fei, and Prakash, B AdityaarXiv preprint arXiv:2503.11835 2025
How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and OutlookLiu, Haoxin, Kamarthi, Harshavardhan, Zhao, Zhiyuan, Xu, Shangqing, Wang, Shiyu, Wen, Qingsong, Hartvigsen, Tom, Wang, Fei, and Prakash, B AdityaarXiv preprint arXiv:2503.11835 2025Time series analysis is a longstanding research topic with wide real-world significance, but compared with language and vision it remains relatively underexplored and isolated. This survey reviews Multiple Modalities for Time Series Analysis (MM4TSA), an emerging area studying how time series analysis can benefit from richer modalities. We systematically discuss three benefits: reusing foundation models from other modalities for efficient time series analysis, multimodal extension for enhanced time series analysis, and cross-modality interaction for advanced time series analysis. We group works by modality type, including text, images, audio, tables, and others, and identify future opportunities in modality selection, heterogeneous modality combinations, and unseen-task generalization.
@article{liu2025mm4tsa, abbr = {mm4tsa25}, title = {How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook}, author = {Liu, Haoxin and Kamarthi, Harshavardhan and Zhao, Zhiyuan and Xu, Shangqing and Wang, Shiyu and Wen, Qingsong and Hartvigsen, Tom and Wang, Fei and Prakash, B Aditya}, journal = {arXiv preprint arXiv:2503.11835}, year = {2025}, selected = {true}, pdf = {https://arxiv.org/abs/2503.11835}, code = {https://github.com/qingsongedu/Awesome-TimeSeries-SpatioTemporal-LM-LLM}, bibtex_show = {true} }
2024
-
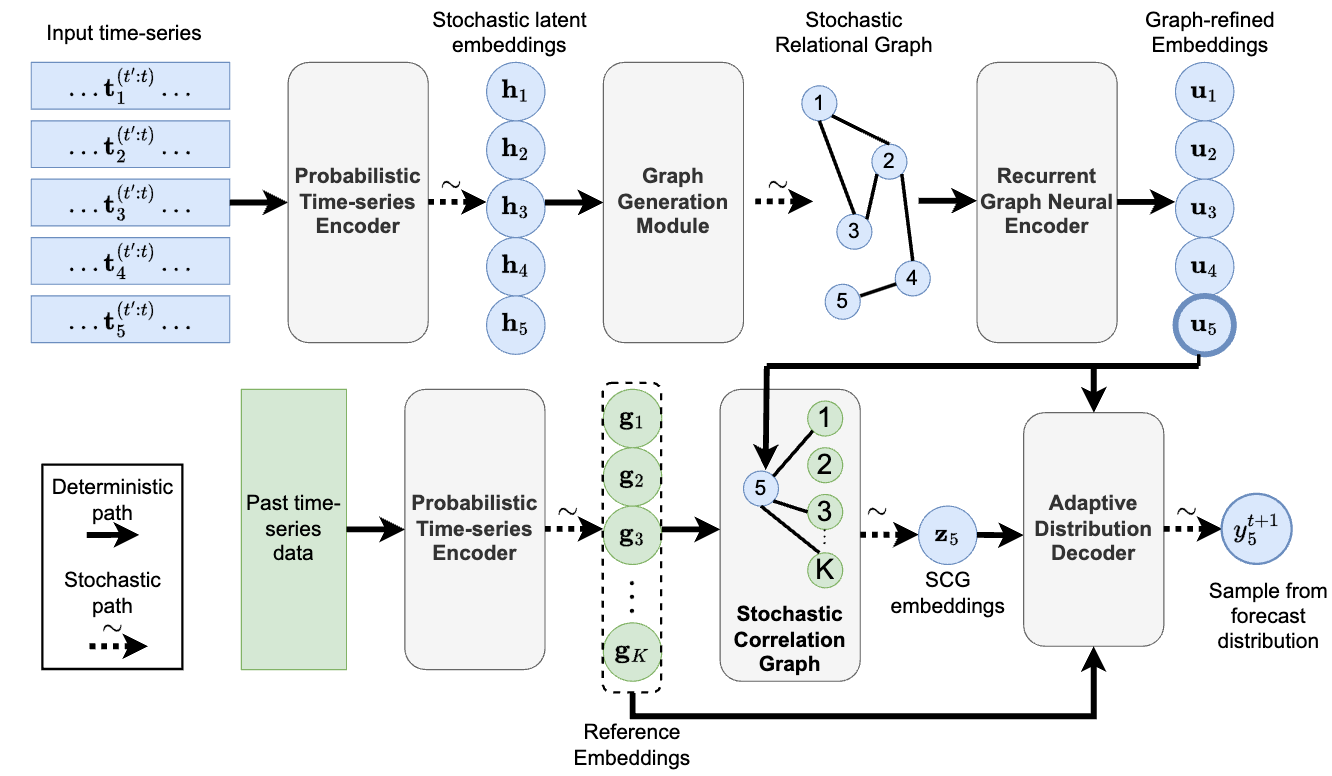 Learning Graph Structures and Uncertainty for Accurate and Calibrated Time-series ForecastingKDD 2024 Workshop on Uncertainty Reasoning and Quantification in Decision Making 2024
Learning Graph Structures and Uncertainty for Accurate and Calibrated Time-series ForecastingKDD 2024 Workshop on Uncertainty Reasoning and Quantification in Decision Making 2024Multi-variate time series forecasting is an important problem with a wide range of applications. Recent works model the relations between time-series as graphs and have shown that propagating information over the relation graph can improve time series forecasting. However, in many cases, relational information is not available or is noisy and reliable. Moreover, most works ignore the underlying uncertainty of time-series both for structure learning and deriving the forecasts resulting in the structure not capturing the uncertainty resulting in forecast distributions with poor uncertainty estimates. We tackle this challenge and introduce STOIC, that leverages stochastic correlations between time-series to learn underlying structure between time-series and to provide well-calibrated and accurate forecasts. Over a wide-range of benchmark datasets STOIC provides around 16% more accurate and 14% better-calibrated forecasts. STOIC also shows better adaptation to noise in data during inference and captures important and useful relational information in various benchmarks.
@article{kamarthi2024stoic, abbr = {stoic24}, title = {Learning Graph Structures and Uncertainty for Accurate and Calibrated Time-series Forecasting}, author = {Kamarthi, Harshavardhan and Kong, Lingkai and Rodriguez, Alexander and Zhang, Chao and Prakash, B Aditya}, journal = {KDD 2024 Workshop on Uncertainty Reasoning and Quantification in Decision Making}, year = {2024}, selected = {true}, pdf = {https://arxiv.org/abs/2407.02641}, bibtex_show = {true}, code = {https://github.com/AdityaLab/STOIC} } -
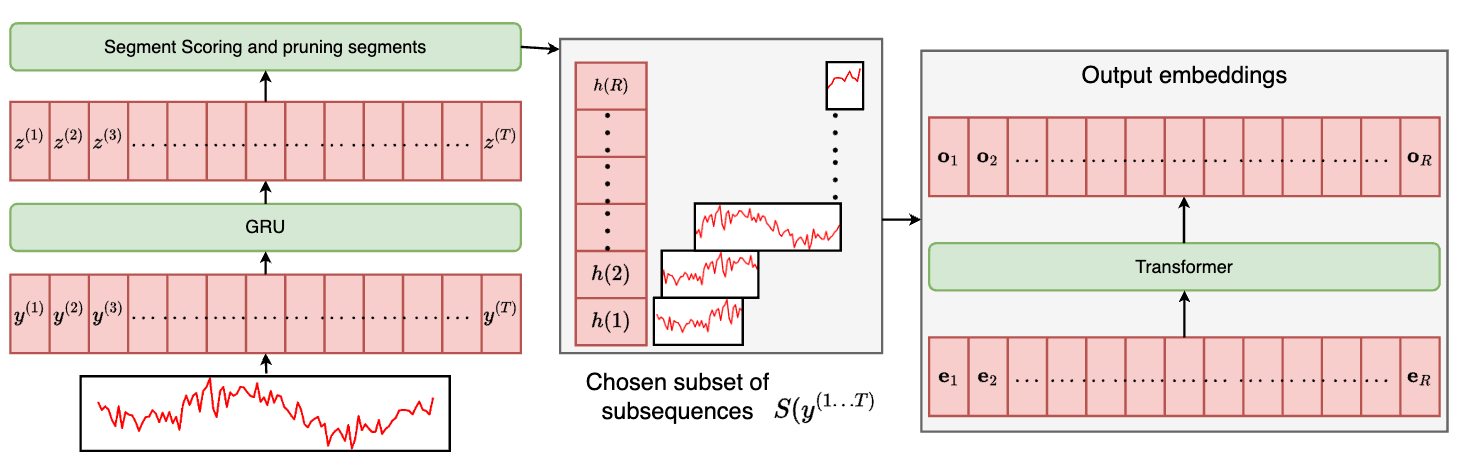 Large Pre-trained time series models for cross-domain Time series analysis tasksKamarthi, Harshavardhan, and Prakash, B AdityaNeurIPS 2024
Large Pre-trained time series models for cross-domain Time series analysis tasksKamarthi, Harshavardhan, and Prakash, B AdityaNeurIPS 2024Large pre-trained models have been vital in recent advancements in domains like language and vision, making model training for individual downstream tasks more efficient and provide superior performance. However, tackling time-series analysis tasks usually involves designing and training a separate model from scratch leveraging training data and domain expertise specific to the task. We tackle a significant challenge for pre-training a foundational time-series model from multi-domain time-series datasets: extracting semantically useful tokenized inputs to the model across heterogenous time-series from different domains. We propose Large Pre-trained Time-series Models (LPTM) that introduces a novel method of adaptive segmentation that automatically identifies optimal dataset-specific segmentation strategy during pre-training. This enables LPTM to perform similar to or better than domain-specific state-of-art model when fine-tuned to different downstream time-series analysis tasks and under zero-shot settings. LPTM achieves superior forecasting and time-series classification results taking up to 40% less data and 50% less training time compared to state-of-art baselines.
@article{kamarthi2023large, abbr = {lptm23}, title = {Large Pre-trained time series models for cross-domain Time series analysis tasks}, author = {Kamarthi, Harshavardhan and Prakash, B Aditya}, journal = {NeurIPS}, year = {2024}, selected = {true}, pdf = {https://arxiv.org/abs/2311.11413}, bibtex_show = {true}, code = {https://github.com/kage08/SegmentTS} } -
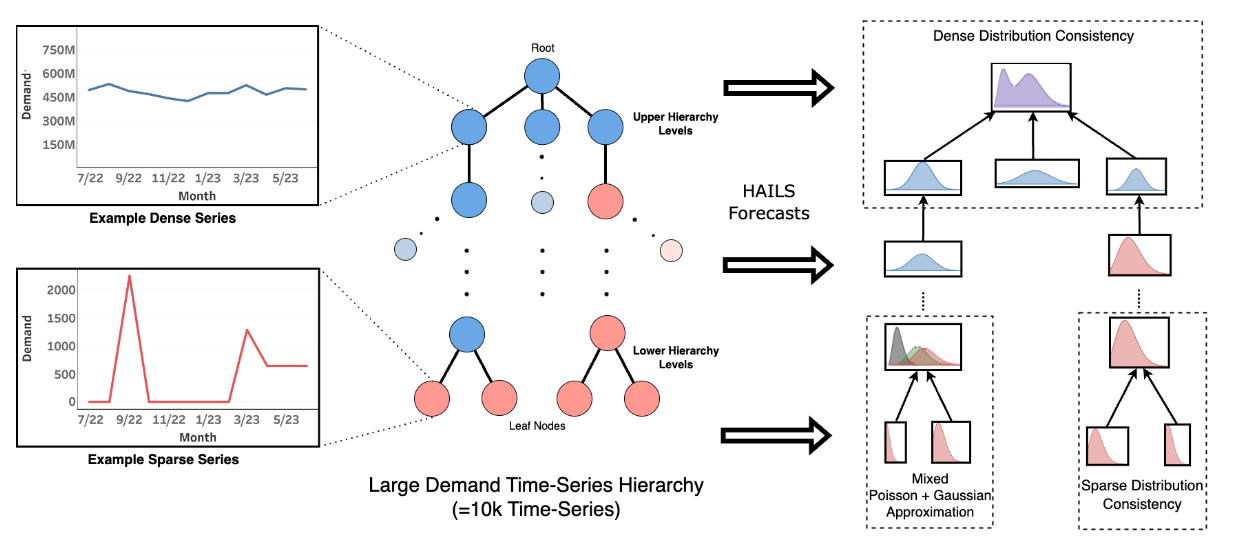 Large Scale Hierarchical Industrial Demand Time-Series Forecasting incorporating SparsityKamarthi, Harshavardhan, Sasanur, Aditya B, Tong, Xinjie, Zhou, Xingyu, Peters, James, Czyzyk, Joe, and Prakash, B AdityaKDD 2024
Large Scale Hierarchical Industrial Demand Time-Series Forecasting incorporating SparsityKamarthi, Harshavardhan, Sasanur, Aditya B, Tong, Xinjie, Zhou, Xingyu, Peters, James, Czyzyk, Joe, and Prakash, B AdityaKDD 2024Hierarchical time-series forecasting (HTSF) is an important problem for many real-world business applications where the goal is to simultaneously forecast multiple time-series that are related to each other via a hierarchical relation. Recent works, however, do not address two important challenges that are typically observed in many demand forecasting applications at large companies. First, many time-series at lower levels of the hierarchy have high sparsity i.e., they have a significant number of zeros. Most HTSF methods do not address this varying sparsity across the hierarchy. Further, they do not scale well to the large size of the real-world hierarchy typically unseen in benchmarks used in literature. We resolve both these challenges by proposing HAILS, a novel probabilistic hierarchical model that enables accurate and calibrated probabilistic forecasts across the hierarchy by adaptively modeling sparse and dense time-series with different distributional assumptions and reconciling them to adhere to hierarchical constraints. We show the scalability and effectiveness of our methods by evaluating them against real-world demand forecasting datasets. We deploy HAILS at a large chemical manufacturing company for a product demand forecasting application with over ten thousand products and observe a significant 8.5% improvement in forecast accuracy and 23% better improvement for sparse time-series. The enhanced accuracy and scalability make HAILS a valuable tool for improved business planning and customer experience.
@article{kamarthi2024hails, abbr = {hails24}, title = {Large Scale Hierarchical Industrial Demand Time-Series Forecasting incorporating Sparsity}, author = {Kamarthi, Harshavardhan and Sasanur, Aditya B and Tong, Xinjie and Zhou, Xingyu and Peters, James and Czyzyk, Joe and Prakash, B Aditya}, journal = {KDD}, pages = {5230--5239}, year = {2024}, selected = {true}, pdf = {https://arxiv.org/abs/2407.02657}, bibtex_show = {true}, code = {https://github.com/AdityaLab/HAILS} } -
 Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant LearningLiu, Haoxin, Kamarthi, Harshavardhan, Kong, Lingkai, Zhao, Zhiyuan, Zhang, Chao, and Prakash, B AdityaIn ICML 2024
Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant LearningLiu, Haoxin, Kamarthi, Harshavardhan, Kong, Lingkai, Zhao, Zhiyuan, Zhang, Chao, and Prakash, B AdityaIn ICML 2024Time-series forecasting (TSF) finds broad applications in real-world scenarios. Due to the dynamic nature of time-series data, it is crucial for TSF models to preserve out-of-distribution (OOD) generalization abilities, as training and test sets represent historical and future data respectively. In this paper, we aim to alleviate the inherent OOD problem in TSF via invariant learning. We identify fundamental challenges of invariant learning for TSF. First, the target variables in TSF may not be sufficiently determined by the input due to unobserved core variables in TSF, breaking the fundamental assumption of invariant learning. Second, time-series datasets lack adequate environment labels, while existing environmental inference methods are not suitable for TSF. To address these challenges, we propose FOIL, a model-agnostic framework that endows time-series forecasting for out-of-distribution generalization via invariant learning. Specifically, FOIL employs a novel surrogate loss to mitigate the impact of unobserved variables. Further, FOIL implements joint optimization by alternately inferring environments effectively with a multi-head network while preserving the temporal adjacency structure and learning invariant representations across inferred environments for OOD generalized TSF. Extensive experiments demonstrate that the proposed FOIL significantly and consistently improves the performance of various TSF models, achieving gains of up to 85%.
@inproceedings{haoxin2024foil, abbr = {foil24}, title = {Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant Learning}, author = {Liu, Haoxin and Kamarthi, Harshavardhan and Kong, Lingkai and Zhao, Zhiyuan and Zhang, Chao and Prakash, B Aditya}, booktitle = {ICML}, pages = {31312--31325}, year = {2024}, selected = {true}, pdf = {https://openreview.net/forum?id=SMUXPVKUBg}, bibtex_show = {true}, code = {https://github.com/AdityaLab/FOIL} } -
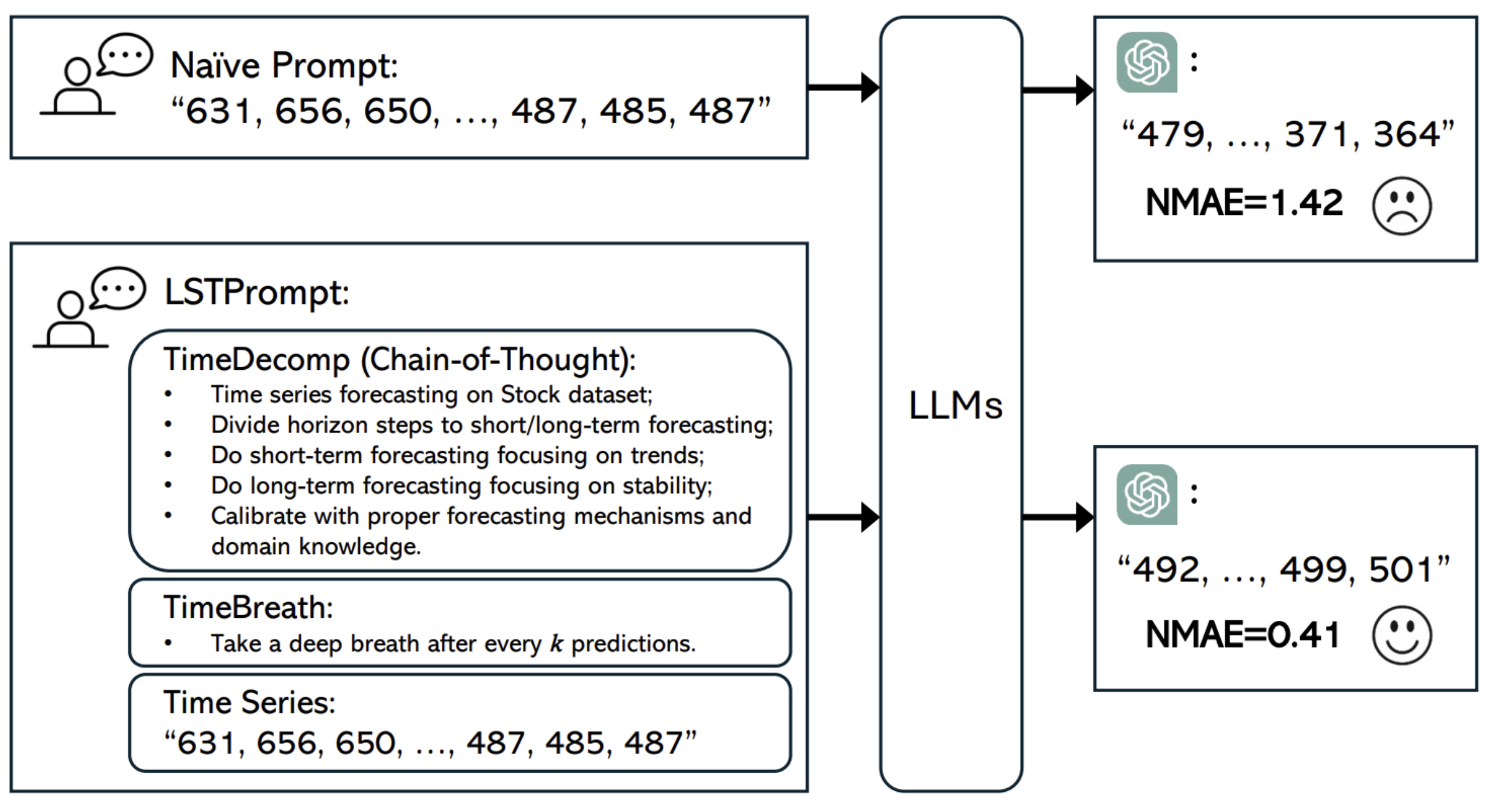 Lstprompt: Large language models as zero-shot time series forecasters by long-short-term promptingACL Findings 2024
Lstprompt: Large language models as zero-shot time series forecasters by long-short-term promptingACL Findings 2024Time-series forecasting (TSF) finds broad applications in real-world scenarios. Prompting off-the-shelf Large Language Models (LLMs) demonstrates strong zero-shot TSF capabilities while preserving computational efficiency. However, existing prompting methods oversimplify TSF as language next-token predictions, overlooking its dynamic nature and lack of integration with state-of-the-art prompt strategies such as Chain-of-Thought. Thus, we propose LSTPrompt, a novel approach for prompting LLMs in zero-shot TSF tasks. LSTPrompt decomposes TSF into short-term and long-term forecasting sub-tasks, tailoring prompts to each. LSTPrompt guides LLMs to regularly reassess forecasting mechanisms to enhance adaptability. Extensive evaluations demonstrate consistently better performance of LSTPrompt than existing prompting methods, and competitive results compared to foundation TSF models.
@article{liu2024lstprompt, abbr = {lstprompt24}, title = {Lstprompt: Large language models as zero-shot time series forecasters by long-short-term prompting}, author = {Liu, Haoxin and Zhao, Zhiyuan and Wang, Jindong and Kamarthi, Harshavardhan and Prakash, B Aditya}, journal = {ACL Findings}, pages = {7832--7840}, year = {2024}, selected = {true}, pdf = {https://arxiv.org/pdf/2402.16132}, bibtex_show = {true}, code = {https://github.com/AdityaLab/lstprompt} } -
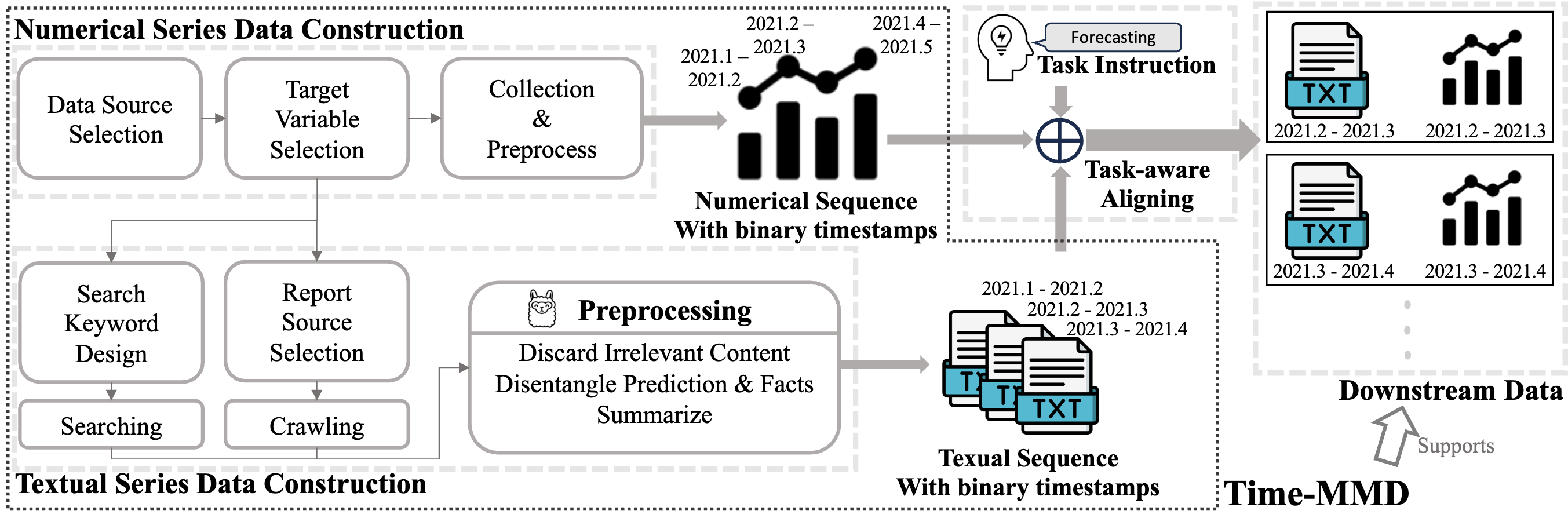 Time-MMD: Multi-Domain Multimodal Dataset for Time Series AnalysisLiu, Haoxin, Xu, Shangqing, Zhao, Zhiyuan, Kong, Lingkai, Kamarthi, Harshavardhan, Sasanur, Aditya B, Sharma, Megha, Cui, Jiaming, Wen, Qingsong, Zhang, Chao, and others,NeurIPS 2024
Time-MMD: Multi-Domain Multimodal Dataset for Time Series AnalysisLiu, Haoxin, Xu, Shangqing, Zhao, Zhiyuan, Kong, Lingkai, Kamarthi, Harshavardhan, Sasanur, Aditya B, Sharma, Megha, Cui, Jiaming, Wen, Qingsong, Zhang, Chao, and others,NeurIPS 2024Time series data are ubiquitous across a wide range of real-world domains. While real-world time series analysis (TSA) requires human experts to integrate numerical series data with multimodal domain-specific knowledge, most existing TSA models rely solely on numerical data, overlooking the significance of information beyond numerical series. This oversight is due to the untapped potential of textual series data and the absence of a comprehensive, high-quality multimodal dataset. To overcome this obstacle, we introduce Time-MMD, the first multi-domain, multimodal time series dataset covering 9 primary data domains. Time-MMD ensures fine-grained modality alignment, eliminates data contamination, and provides high usability. Additionally, we develop MM-TSFlib, the first multimodal time-series forecasting (TSF) library, seamlessly pipelining multimodal TSF evaluations based on Time-MMD for in-depth analyses. Extensive experiments conducted on Time-MMD through MM-TSFlib demonstrate significant performance enhancements by extending unimodal TSF to multimodality, evidenced by over 15% mean squared error reduction in general, and up to 40% in domains with rich textual data. More importantly, our datasets and library revolutionize broader applications, impacts, research topics to advance TSA.
@article{liu2024time, abbr = {timemmd24}, title = {Time-MMD: Multi-Domain Multimodal Dataset for Time Series Analysis}, author = {Liu, Haoxin and Xu, Shangqing and Zhao, Zhiyuan and Kong, Lingkai and Kamarthi, Harshavardhan and Sasanur, Aditya B and Sharma, Megha and Cui, Jiaming and Wen, Qingsong and Zhang, Chao and others}, journal = {NeurIPS}, year = {2024}, selected = {true}, pdf = {https://arxiv.org/abs/2406.08627}, bibtex_show = {true}, code = {https://github.com/AdityaLab/Time-MMD} } -
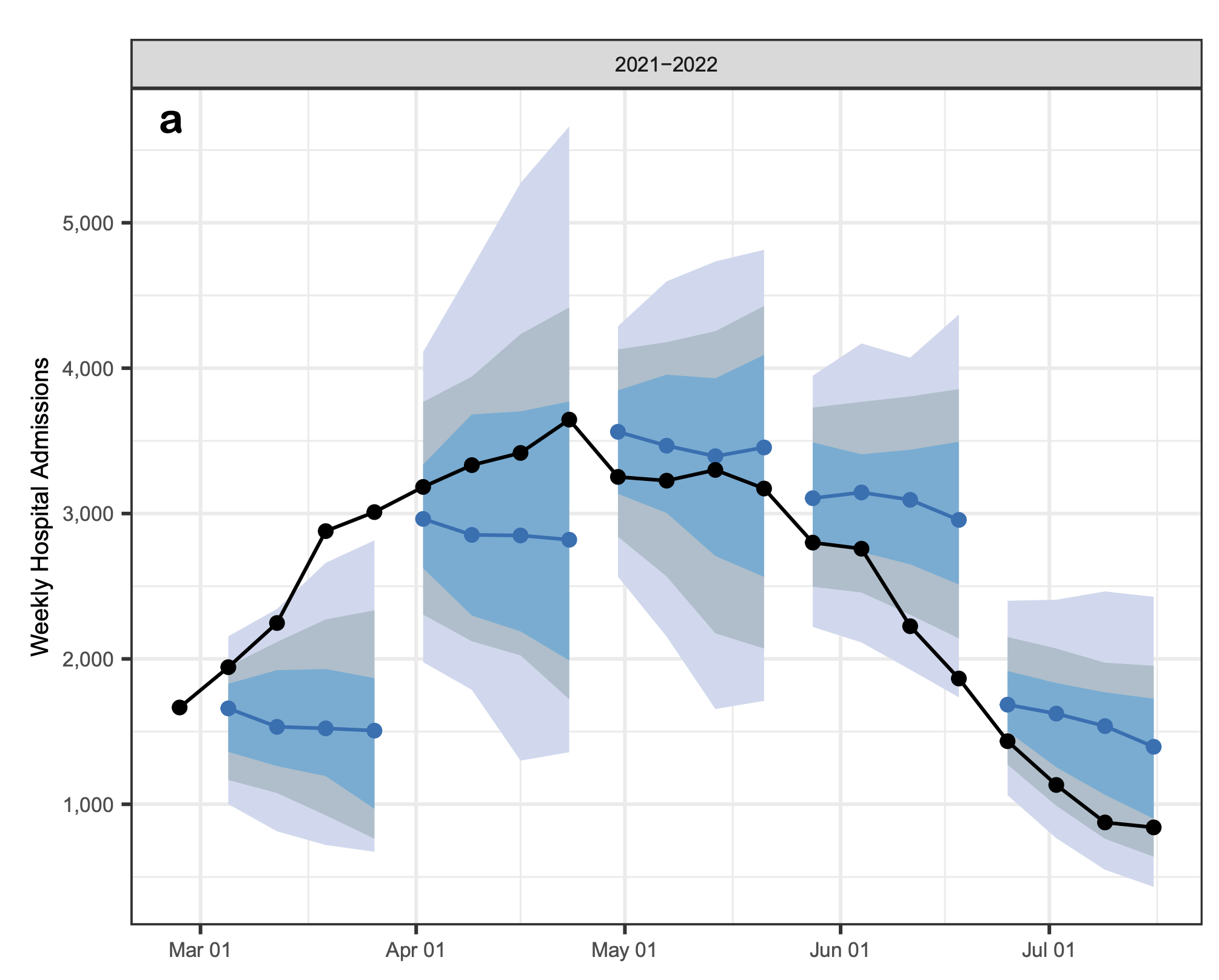 Title evaluation of FluSight influenza forecasting in the 2021–22 and 2022–23 seasons with a new target laboratory-confirmed influenza hospitalizationsMathis, Sarabeth M, Webber, Alexander E, León, Tomás M, Murray, Erin L, Sun, Monica, White, Lauren A, Brooks, Logan C, Green, Alden, Hu, Addison J, Rosenfeld, Roni, and others,Nature Communications 2024
Title evaluation of FluSight influenza forecasting in the 2021–22 and 2022–23 seasons with a new target laboratory-confirmed influenza hospitalizationsMathis, Sarabeth M, Webber, Alexander E, León, Tomás M, Murray, Erin L, Sun, Monica, White, Lauren A, Brooks, Logan C, Green, Alden, Hu, Addison J, Rosenfeld, Roni, and others,Nature Communications 2024Accurate forecasts can enable more effective public health responses during seasonal influenza epidemics. For the 2021–22 and 2022–23 influenza seasons, 26 forecasting teams provided national and jurisdiction-specific probabilistic predictions of weekly confirmed influenza hospital admissions for one-to-four weeks ahead. Forecast skill is evaluated using the Weighted Interval Score (WIS), relative WIS, and coverage. Six out of 23 models outperform the baseline model across forecast weeks and locations in 2021–22 and 12 out of 18 models in 2022–23. Averaging across all forecast targets, the FluSight ensemble is the 2nd most accurate model measured by WIS in 2021–22 and the 5th most accurate in the 2022–23 season. Forecast skill and 95% coverage for the FluSight ensemble and most component models degrade over longer forecast horizons. In this work we demonstrate that while the FluSight ensemble was a robust predictor, even ensembles face challenges during periods of rapid change.
@article{mathis2024title, abbr = {nature24}, title = {Title evaluation of FluSight influenza forecasting in the 2021--22 and 2022--23 seasons with a new target laboratory-confirmed influenza hospitalizations}, author = {Mathis, Sarabeth M and Webber, Alexander E and Le{\'o}n, Tom{\'a}s M and Murray, Erin L and Sun, Monica and White, Lauren A and Brooks, Logan C and Green, Alden and Hu, Addison J and Rosenfeld, Roni and others}, journal = {Nature Communications}, year = {2024}, selected = {true}, pdf = {https://www.nature.com/articles/s41467-024-50601-9}, bibtex_show = {true} } -
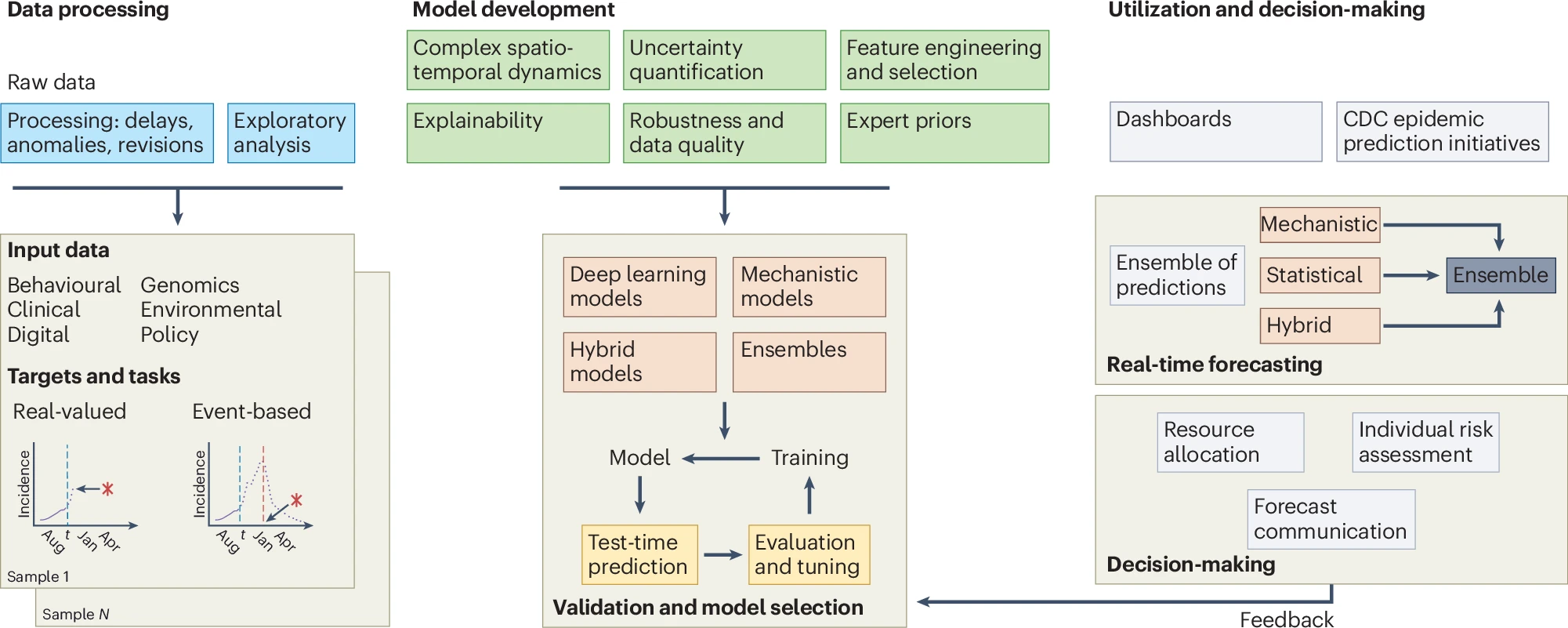 Machine learning for data-centric epidemic forecastingRodrı́guez, Alexander, Kamarthi, Harshavardhan, Agarwal, Pulak, Ho, Javen, Patel, Mira, Sapre, Suchet, and Prakash, B AdityaNature Machine Intelligence 2024
Machine learning for data-centric epidemic forecastingRodrı́guez, Alexander, Kamarthi, Harshavardhan, Agarwal, Pulak, Ho, Javen, Patel, Mira, Sapre, Suchet, and Prakash, B AdityaNature Machine Intelligence 2024The COVID-19 pandemic emphasized the importance of epidemic forecasting for decision makers in multiple domains, ranging from public health to the economy. Forecasting epidemic progression is a non-trivial task due to multiple confounding factors, such as human behaviour, pathogen dynamics and environmental conditions. However, the surge in research interest and initiatives from public health and funding agencies has fuelled the availability of new data sources that capture previously unobservable aspects of disease spread, paving the way for a spate of ‘data-centred’ computational solutions that show promise for enhancing our forecasting capabilities. Here we discuss various methodological and practical advances and introduce a conceptual framework to navigate through them. First we list relevant datasets, such as symptomatic online surveys, retail and commerce, mobility and genomics data. Next we consider methods, focusing on recent data-driven statistical and deep learning-based methods, as well as hybrid models that combine domain knowledge of mechanistic models with the flexibility of statistical approaches. We also discuss experiences and challenges that arise in the real-world deployment of these forecasting systems, including decision-making informed by forecasts. Finally, we highlight some challenges and open problems found across the forecasting pipeline to enable robust future pandemic preparedness.
@article{rodriguez2024machine, abbr = {survey24}, title = {Machine learning for data-centric epidemic forecasting}, author = {Rodr{\'\i}guez, Alexander and Kamarthi, Harshavardhan and Agarwal, Pulak and Ho, Javen and Patel, Mira and Sapre, Suchet and Prakash, B Aditya}, journal = {Nature Machine Intelligence}, volume = {6}, number = {10}, pages = {1122--1131}, year = {2024}, selected = {true}, pdf = {https://www.nature.com/articles/s42256-024-00895-7}, bibtex_show = {true} }
2023
-
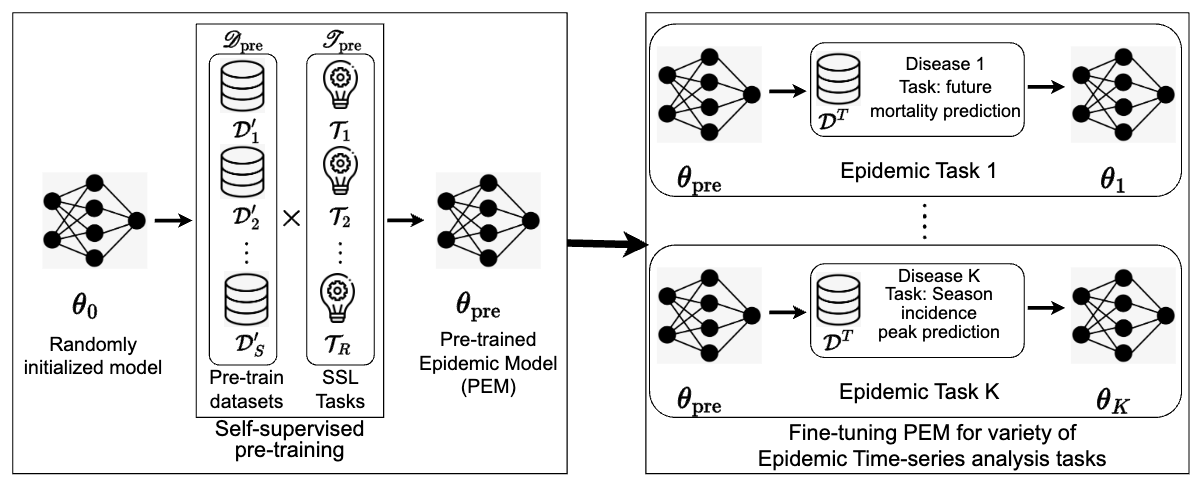 PEMS: Pre-trained Epidmic Time-series ModelsKamarthi, Harshavardhan, and Prakash, B AdityaarXiv preprint arXiv:2311.07841 2023
PEMS: Pre-trained Epidmic Time-series ModelsKamarthi, Harshavardhan, and Prakash, B AdityaarXiv preprint arXiv:2311.07841 2023Providing accurate and reliable predictions about the future of an epidemic is an important problem for enabling informed public health decisions. Recent works have shown that leveraging data-driven solutions that utilize advances in deep learning methods to learn from past data of an epidemic often outperform traditional mechanistic models. However, in many cases, the past data is sparse and may not sufficiently capture the underlying dynamics. While there exists a large amount of data from past epidemics, leveraging prior knowledge from time-series data of other diseases is a non-trivial challenge. Motivated by the success of pre-trained models in language and vision tasks, we tackle the problem of pre-training epidemic time-series models to learn from multiple datasets from different diseases and epidemics. We introduce Pre-trained Epidemic Time-Series Models (PEMS) that learn from diverse time-series datasets of a variety of diseases by formulating pre-training as a set of self-supervised learning (SSL) tasks. We tackle various important challenges specific to pre-training for epidemic time-series such as dealing with heterogeneous dynamics and efficiently capturing useful patterns from multiple epidemic datasets by carefully designing the SSL tasks to learn important priors about the epidemic dynamics that can be leveraged for fine-tuning to multiple downstream tasks. The resultant PEM outperforms previous state-of-the-art methods in various downstream time-series tasks across datasets of varying seasonal patterns, geography, and mechanism of contagion including the novel Covid-19 pandemic unseen in pre-trained data with better efficiency using smaller fraction of datasets.
@article{kamarthi2023pems, abbr = {pems23}, title = {PEMS: Pre-trained Epidmic Time-series Models}, author = {Kamarthi, Harshavardhan and Prakash, B Aditya}, journal = {arXiv preprint arXiv:2311.07841}, year = {2023}, selected = {true}, pdf = {https://arxiv.org/abs/2311.07841}, bibtex_show = {true} } -
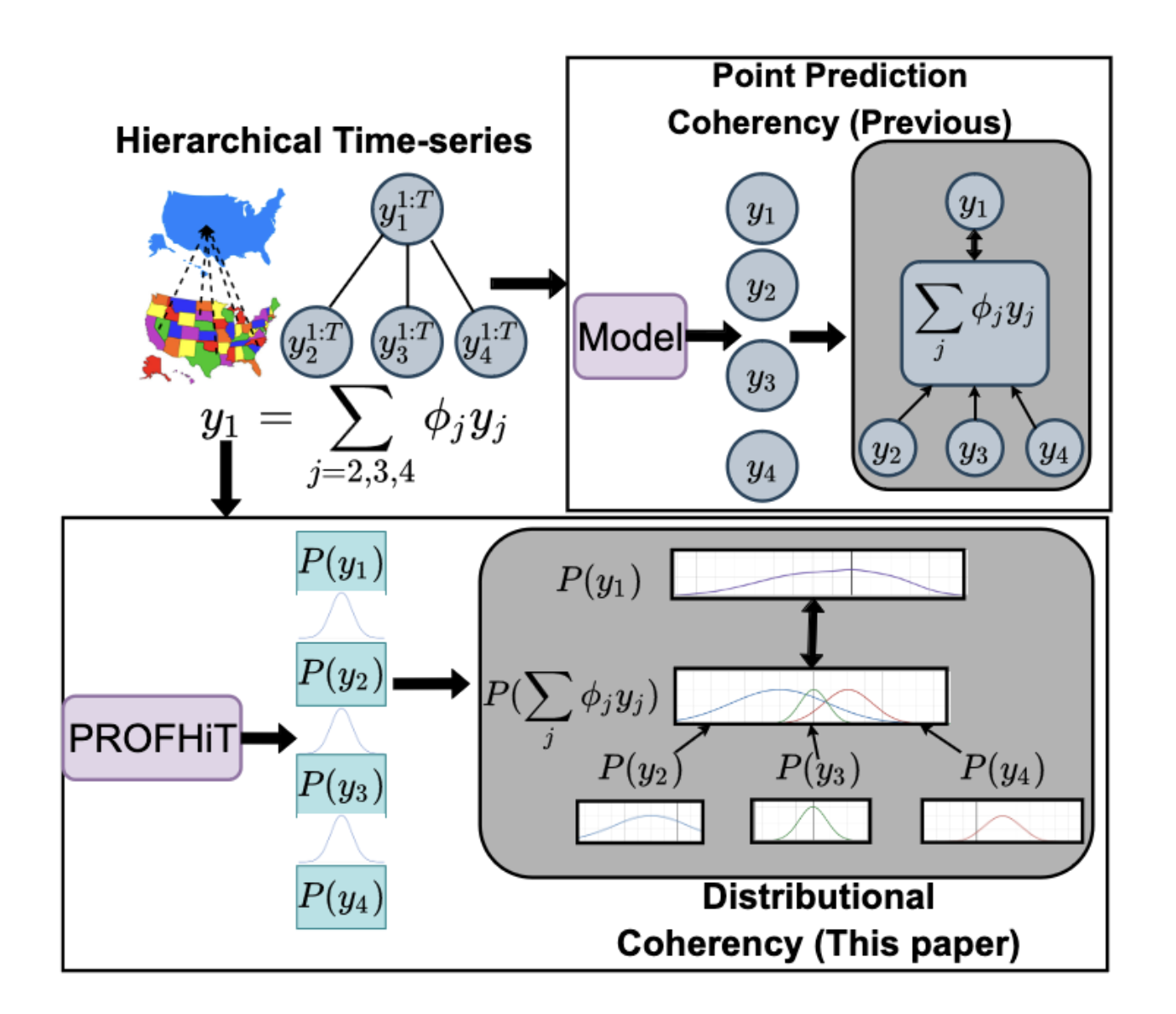 PROFHIT: Probabilistic Robust Forecasting for Hierarchical Time-seriesKDD 2023
PROFHIT: Probabilistic Robust Forecasting for Hierarchical Time-seriesKDD 2023Many multivariate time-series that have underlying hierarchical relations. Probabilistic hierarchical time-series forecasting is an important variant of time-series forecasting, where the goal is to model and forecast multivariate time-series. We propose PROFHIT, a state-of-art probabilistic model that provides accurate probabilitic forecasts that adhere to hierarchical relations at distributional level and adapts to datasets with different levels of adherance to the hierarchy.
@article{kamarthi2023profhit, abbr = {profhit23}, title = {PROFHIT: Probabilistic Robust Forecasting for Hierarchical Time-series}, author = {Kamarthi, Harshavardhan and Kong, Lingkai and Rodr{\'\i}guez, Alexander and Zhang, Chao and Prakash, B Aditya}, journal = {KDD}, year = {2023}, selected = {true}, pdf = {https://arxiv.org/abs/2206.07940}, bibtex_show = {true}, code = {https://github.com/AdityaLab/CAMul} }
2022
-
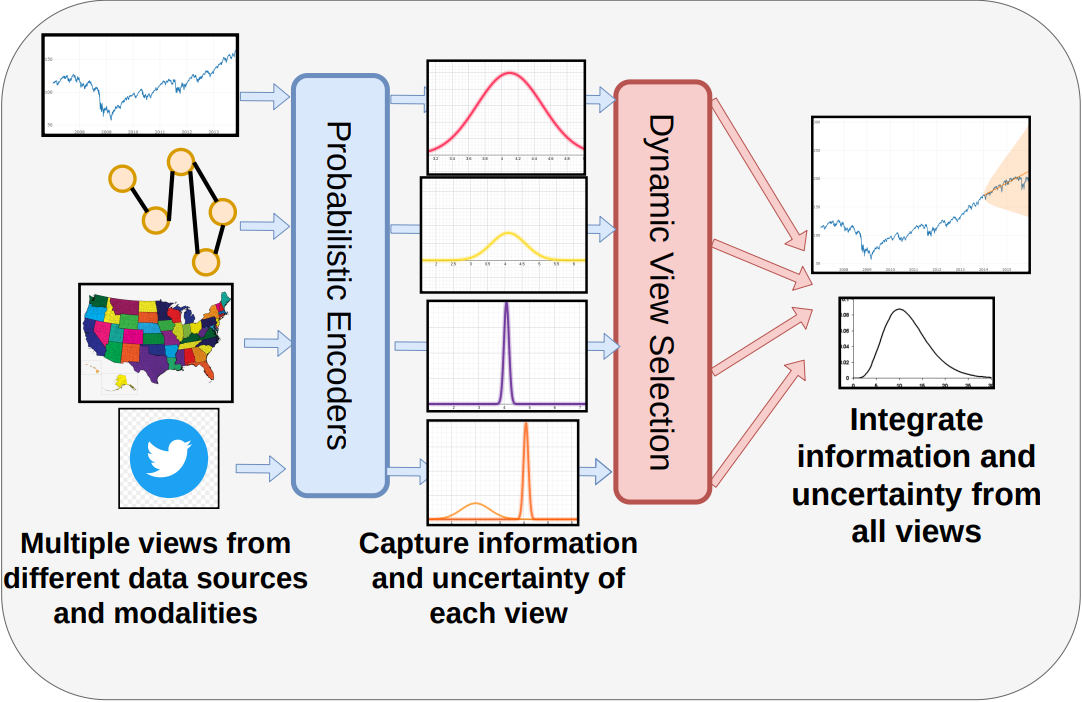 CAMul: Calibrated and Accurate Multi-view Time-Series ForecastingACM Web Conference (WWW) 2022
CAMul: Calibrated and Accurate Multi-view Time-Series ForecastingACM Web Conference (WWW) 2022Probabilistic time-series forecasting enables reliable decision making across many domains. Most forecasting problems have diverse sources of data containing multiple modalities and structures. Leveraging information as well as uncertainty from these data sources for well-calibrated and accurate forecasts is an important challenging problem. Most previous work on multi-modal learning and forecasting simply aggregate intermediate representations from each data view by simple methods of summation or concatenation and do not explicitly model uncertainty for each data-view. We propose a general probabilistic multi-view forecasting framework CAMul, that can learn representations and uncertainty from diverse data sources. It integrates the knowledge and uncertainty from each data view in a dynamic context-specific manner assigning more importance to useful views to model a well-calibrated forecast distribution. We use CAMul for multiple domains with varied sources and modalities and show that CAMul outperforms other state-of-art probabilistic forecasting models by over 25% in accuracy and calibration.
@article{kamarthi2021camul, abbr = {camul21}, title = {CAMul: Calibrated and Accurate Multi-view Time-Series Forecasting}, author = {Kamarthi, Harshavardhan and Kong, Lingkai and Rodr{\'\i}guez, Alexander and Zhang, Chao and Prakash, B Aditya}, journal = {ACM Web Conference (WWW)}, year = {2022}, selected = {true}, pdf = {https://arxiv.org/abs/2109.07438}, bibtex_show = {true}, code = {https://github.com/AdityaLab/CAMul} } -
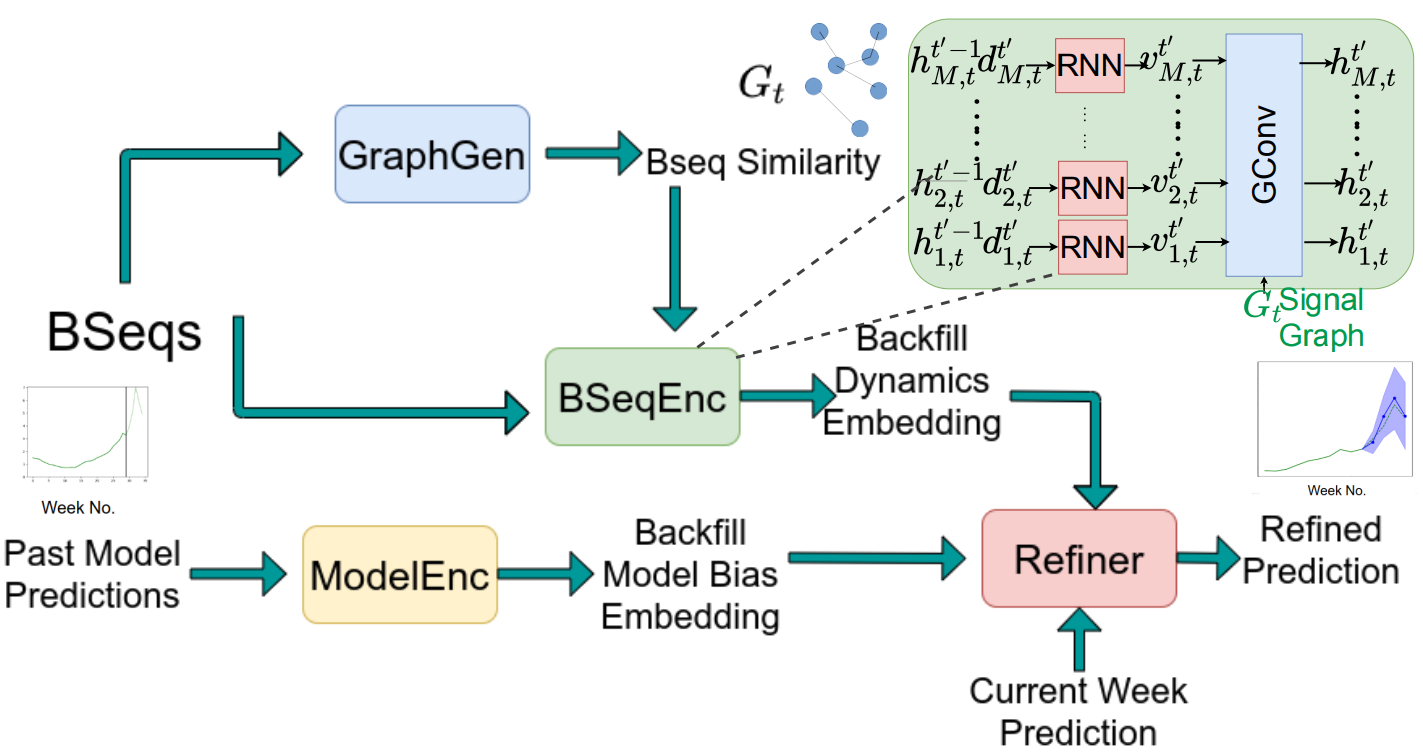 Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in FutureKamarthi, Harshavardhan, Rodrı́guez, Alexander, and Prakash, B AdityaICLR 2022
Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in FutureKamarthi, Harshavardhan, Rodrı́guez, Alexander, and Prakash, B AdityaICLR 2022In real-time forecasting in public health, data collection is a non-trivial and demanding task. Often after initially released, it undergoes several revisions later (maybe due to human or technical constraints) - as a result, it may take weeks until the data reaches to a stable value. This so-called ’backfill’ phenomenon and its effect on model performance has been barely studied in the prior literature. In this paper, we introduce the multi-variate backfill problem using COVID-19 as the motivating example. We construct a detailed dataset composed of relevant signals over the past year of the pandemic. We then systematically characterize several patterns in backfill dynamics and leverage our observations for formulating a novel problem and neural framework Back2Future that aims to refines a given model’s predictions in real-time. Our extensive experiments demonstrate that our method refines the performance of top models for COVID-19 forecasting, in contrast to non-trivial baselines, yielding 18% improvement over baselines, enabling us obtain a new SOTA performance. In addition, we show that our model improves model evaluation too; hence policy-makers can better understand the true accuracy of forecasting models in real-time.
@article{kamarthi2021back2future, abbr = {back2future21}, title = {Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in Future}, author = {Kamarthi, Harshavardhan and Rodr{\'\i}guez, Alexander and Prakash, B Aditya}, journal = {ICLR}, year = {2022}, selected = {true}, pdf = {https://arxiv.org/abs/2106.04420}, bibtex_show = {true}, code = {https://github.com/AdityaLab/Back2Future} }
2021
-
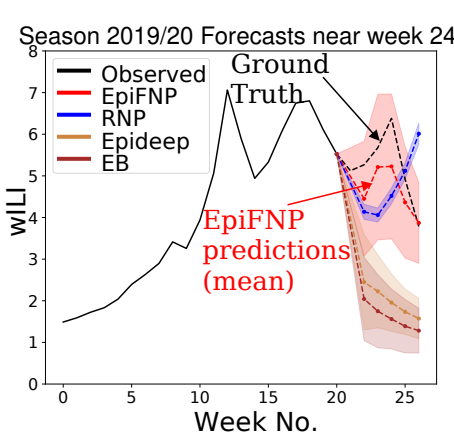 When in Doubt: Neural Non-Parametric Uncertainty Quantification for Epidemic ForecastingThirty-fifth Conference on Neural Information Processing Systems (NeurIPS) 2021
When in Doubt: Neural Non-Parametric Uncertainty Quantification for Epidemic ForecastingThirty-fifth Conference on Neural Information Processing Systems (NeurIPS) 2021Accurate and trustworthy epidemic forecasting is an important problem that has impact on public health planning and disease mitigation. Most existing epidemic forecasting models disregard uncertainty quantification, resulting in mis-calibrated predictions. Recent works in deep neural models for uncertainty-aware time-series forecasting also have several limitations; e.g. it is difficult to specify meaningful priors in Bayesian NNs, while methods like deep ensembling are computationally expensive in practice. In this paper, we fill this important gap. We model the forecasting task as a probabilistic generative process and propose a functional neural process model called EPIFNP, which directly models the probability density of the forecast value. EPIFNP leverages a dynamic stochastic correlation graph to model the correlations between sequences in a non-parametric way, and designs different stochastic latent variables to capture functional uncertainty from different perspectives. Our extensive experiments in a real-time flu forecasting setting show that EPIFNP significantly outperforms previous state-of-the-art models in both accuracy and calibration metrics, up to 2.5x in accuracy and 2.4x in calibration. Additionally, due to properties of its generative process,EPIFNP learns the relations between the current season and similar patterns of historical seasons,enabling interpretable forecasts. Beyond epidemic forecasting, the EPIFNP can be of independent interest for advancing principled uncertainty quantification in deep sequential models for predictive analytics.
@article{kamarthi2021doubt, abbr = {epifnp21}, title = {When in Doubt: Neural Non-Parametric Uncertainty Quantification for Epidemic Forecasting}, author = {Kamarthi, Harshavardhan and Kong, Lingkai and Rodr{\'\i}guez, Alexander and Zhang, Chao and Prakash, B Aditya}, journal = {Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS)}, year = {2021}, selected = {true}, pdf = {https://arxiv.org/abs/2106.03904}, bibtex_show = {true}, code = {https://github.com/AdityaLab/EpiFNP} } -
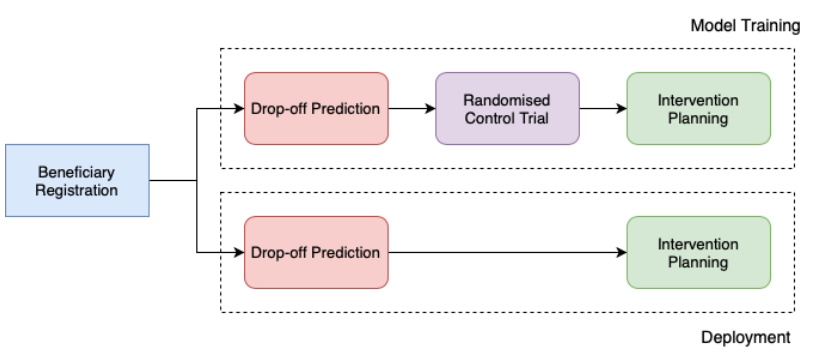 Selective Intervention Planning using Restless Multi-Armed Bandits to Improve Maternal and Child Health OutcomesNishtala, Siddharth, Madaan, Lovish, Mate, Aditya, Kamarthi, Harshavardhan, Grama, Anirudh, Thakkar, Divy, Narayanan, Dhyanesh, Chaudhary, Suresh, Madhiwalla, Neha, Padmanabhan, Ramesh, and others,arXiv preprint arXiv:2103.09052 2021
Selective Intervention Planning using Restless Multi-Armed Bandits to Improve Maternal and Child Health OutcomesNishtala, Siddharth, Madaan, Lovish, Mate, Aditya, Kamarthi, Harshavardhan, Grama, Anirudh, Thakkar, Divy, Narayanan, Dhyanesh, Chaudhary, Suresh, Madhiwalla, Neha, Padmanabhan, Ramesh, and others,arXiv preprint arXiv:2103.09052 2021India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low resource households. We partner with ARMMAN, a non-profit based in India employing a call-based information program to disseminate health-related information to pregnant women and women with recent child deliveries. We analyze call records of over 300,000 women registered in the program created by ARMMAN and try to identify women who might not engage with these call programs that are proven to result in positive health outcomes. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries’ demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model’s predictions to make interventions boosts engagement metrics by 61.37%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
@article{nishtala2021selective, abbr = {selective20}, title = {Selective Intervention Planning using Restless Multi-Armed Bandits to Improve Maternal and Child Health Outcomes}, author = {Nishtala, Siddharth and Madaan, Lovish and Mate, Aditya and Kamarthi, Harshavardhan and Grama, Anirudh and Thakkar, Divy and Narayanan, Dhyanesh and Chaudhary, Suresh and Madhiwalla, Neha and Padmanabhan, Ramesh and others}, journal = {arXiv preprint arXiv:2103.09052}, year = {2021}, pdf = {https://arxiv.org/abs/2103.09052}, bibtex_show = {true}, selected = {true} }
2020
-
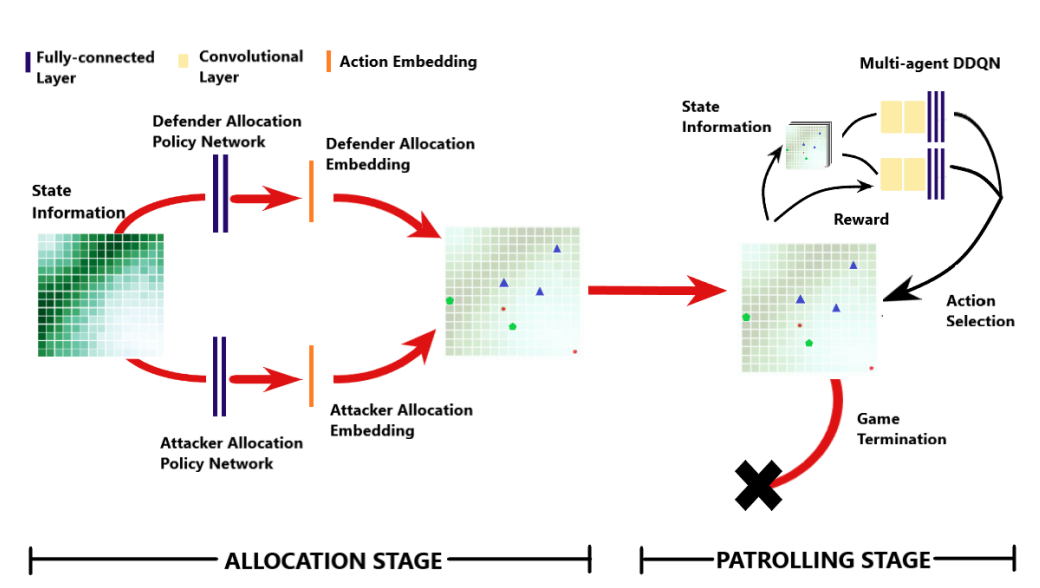 Reinforcement Learning for Unified Allocation and Patrolling in Signaling Games with UncertaintyVenugopal, Aravind, Bondi, Elizabeth, Kamarthi, Harshavardhan, Dholakia, Keval, Ravindran, Balaraman, and Tambe, Milind20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2020
Reinforcement Learning for Unified Allocation and Patrolling in Signaling Games with UncertaintyVenugopal, Aravind, Bondi, Elizabeth, Kamarthi, Harshavardhan, Dholakia, Keval, Ravindran, Balaraman, and Tambe, Milind20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2020Green Security Games (GSGs) have been successfully used in the protection of valuable resources such as fisheries, forests and wildlife. While real-world deployment involves both resource allocation and subsequent coordinated patrolling with communication and real-time, uncertain information, previous game models do not fully address both of these stages simultaneously. Furthermore, adopting existing solution strategies is difficult since they do not scale well for larger, more complex variants of the game models. We therefore first propose a novel GSG model that combines defender allocation, patrolling, real-time drone notification to human patrollers, and drones sending warning signals to attackers. The model further incorporates uncertainty for real-time decision-making within a team of drones and human patrollers. Second, we present CombSGPO, a novel and scalable algorithm based on reinforcement learning, to compute a defender strategy for this game model. CombSGPO performs policy search over a multi-dimensional, discrete action space to compute an allocation strategy that is best suited to a best-response patrolling strategy for the defender, learnt by training a multi-agent Deep Q-Network. We show via experiments that CombSGPO converges to better strategies and is more scalable than comparable approaches. Third, we provide a detailed analysis of the coordination and signaling behavior learnt by CombSGPO, showing group formation between defender resources and patrolling formations based on signaling and notifications between resources. Importantly, we find that strategic signaling emerges in the final learnt strategy. Finally, we perform experiments to evaluate these strategies under different levels of uncertainty.
@article{venugopal2020reinforcement, abbr = {patrol20}, title = {Reinforcement Learning for Unified Allocation and Patrolling in Signaling Games with Uncertainty}, author = {Venugopal, Aravind and Bondi, Elizabeth and Kamarthi, Harshavardhan and Dholakia, Keval and Ravindran, Balaraman and Tambe, Milind}, journal = {20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS)}, year = {2020}, pdf = {https://arxiv.org/abs/2012.10389}, bibtex_show = {true}, selected = {true} } -
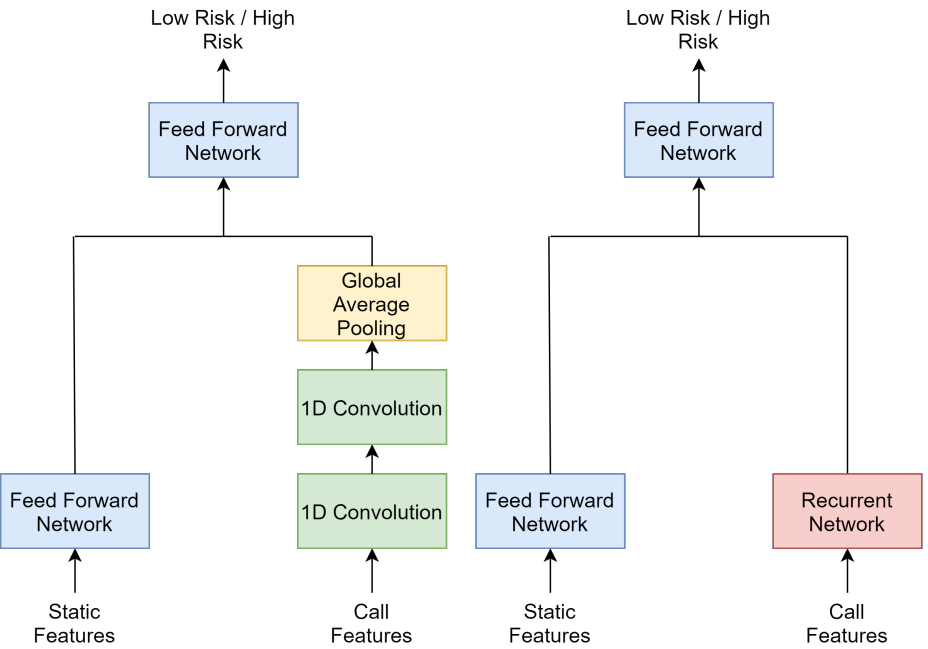 Missed calls, Automated Calls and Health Support: Using AI to improve maternal health outcomes by increasing program engagementNishtala, Siddharth, Kamarthi, Harshavardhan, Thakkar, Divy, Narayanan, Dhyanesh, Grama, Anirudh, Hegde, Aparna, Padmanabhan, Ramesh, Madhiwalla, Neha, Chaudhary, Suresh, Ravindran, Balaraman, and others,Harvard CRCS Workshop on AI for Social Good 2020
Missed calls, Automated Calls and Health Support: Using AI to improve maternal health outcomes by increasing program engagementNishtala, Siddharth, Kamarthi, Harshavardhan, Thakkar, Divy, Narayanan, Dhyanesh, Grama, Anirudh, Hegde, Aparna, Padmanabhan, Ramesh, Madhiwalla, Neha, Chaudhary, Suresh, Ravindran, Balaraman, and others,Harvard CRCS Workshop on AI for Social Good 2020India accounts for 11% of maternal deaths globally where a woman dies in childbirth every fifteen minutes. Lack of access to preventive care information is a significant problem contributing to high maternal morbidity and mortality numbers, especially in low-income households. We work with ARMMAN, a non-profit based in India, to further the use of call-based information programs by early-on identifying women who might not engage on these programs that are proven to affect health parameters positively.We analyzed anonymized call-records of over 300,000 women registered in an awareness program created by ARMMAN that uses cellphone calls to regularly disseminate health related information. We built robust deep learning based models to predict short term and long term dropout risk from call logs and beneficiaries’ demographic information. Our model performs 13% better than competitive baselines for short-term forecasting and 7% better for long term forecasting. We also discuss the applicability of this method in the real world through a pilot validation that uses our method to perform targeted interventions.
@article{nishtala2020missed, abbr = {missedcall20}, title = {Missed calls, Automated Calls and Health Support: Using AI to improve maternal health outcomes by increasing program engagement}, author = {Nishtala, Siddharth and Kamarthi, Harshavardhan and Thakkar, Divy and Narayanan, Dhyanesh and Grama, Anirudh and Hegde, Aparna and Padmanabhan, Ramesh and Madhiwalla, Neha and Chaudhary, Suresh and Ravindran, Balaraman and others}, journal = {Harvard CRCS Workshop on AI for Social Good}, year = {2020}, bibtex_show = {true}, selected = {true}, pdf = {https://arxiv.org/abs/2006.07590} }
2019
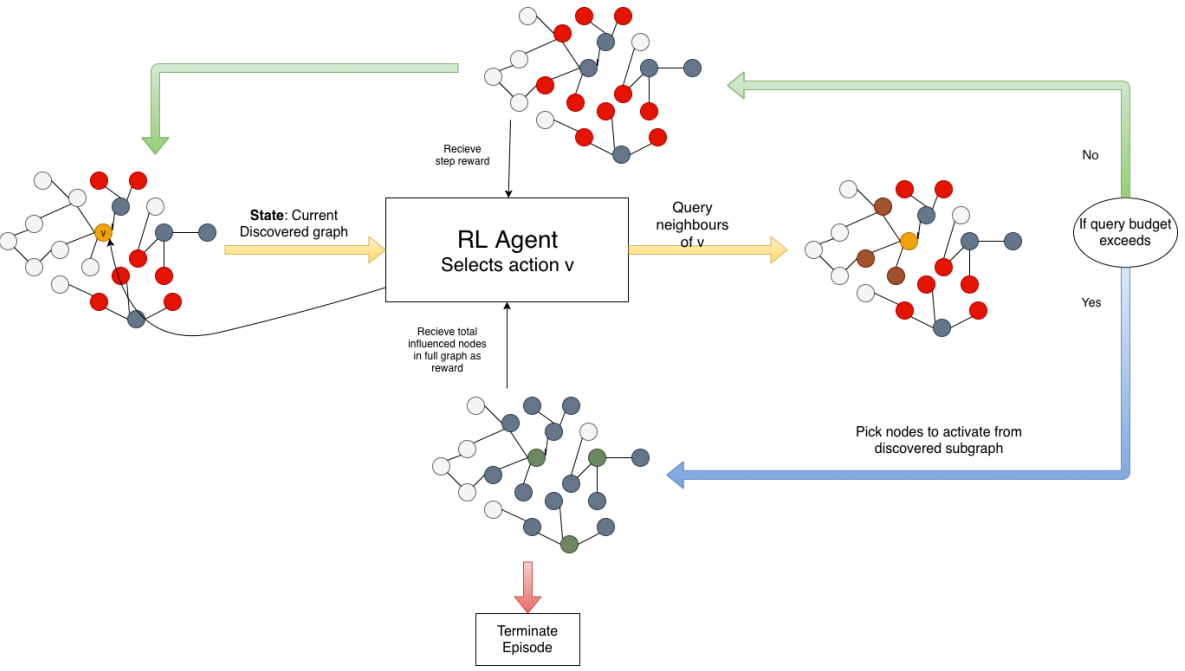 Influence maximization in unknown social networks: Learning Policies for Effective Graph SamplingKamarthi, Harshavardhan, Vijayan, Priyesh, Wilder, Bryan, Ravindran, Balaraman, and Tambe, Milind19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), Nominated for Best Paper Award<\b> </em> 2019 </div>
Influence maximization in unknown social networks: Learning Policies for Effective Graph SamplingKamarthi, Harshavardhan, Vijayan, Priyesh, Wilder, Bryan, Ravindran, Balaraman, and Tambe, Milind19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), Nominated for Best Paper Award<\b> </em> 2019 </div>A serious challenge when finding influential actors in real-world social networks is the lack of knowledge about the structure of the underlying network. Current state-of-the-art methods rely on hand-crafted sampling algorithms; these methods sample nodes and their neighbours in a carefully constructed order and choose opinion leaders from this discovered network to maximize influence spread in the (unknown) complete network. In this work, we propose a reinforcement learning framework for network discovery that automatically learns useful node and graph representations that encode important structural properties of the network. At training time, the method identifies portions of the network such that the nodes selected from this sampled subgraph can effectively influence nodes in the complete network. The realization of such transferable network structure based adaptable policies is attributed to the meticulous design of the framework that encodes relevant node and graph signatures driven by an appropriate reward scheme. We experiment with real-world social networks from four different domains and show that the policies learned by our RL agent provide a 10-36% improvement over the current state-of-the-art method.
</div> </div> </li>@article{kamarthi2019influence, abbr = {influence19}, title = {Influence maximization in unknown social networks: Learning Policies for Effective Graph Sampling}, author = {Kamarthi, Harshavardhan and Vijayan, Priyesh and Wilder, Bryan and Ravindran, Balaraman and Tambe, Milind}, journal = {19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), <b>Nominated for Best Paper Award<\b> }, note = {Nominated for best paper award}, year = {2019}, selected = {true}, pdf = {https://arxiv.org/abs/1907.11625}, bibtex_show = {true}, code = {https://github.com/kage08/graph_sample_rl} }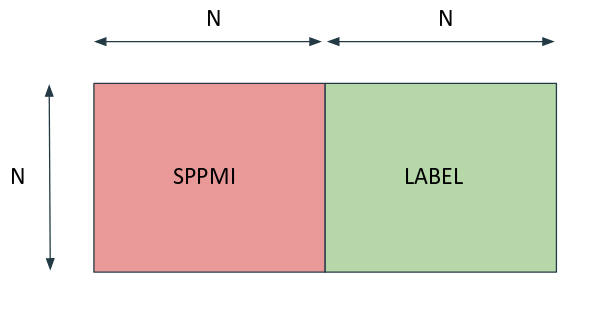 Integrating Lexical Knowledge in Word Embeddings using Sprinkling and RetrofittingSrinivasan, Aakash, Kamarthi, Harshavardhan, Ganesan, Devi, and Chakraborti, SutanuInternational Conference on Natural Language Processing (ICNLP) 2019
Integrating Lexical Knowledge in Word Embeddings using Sprinkling and RetrofittingSrinivasan, Aakash, Kamarthi, Harshavardhan, Ganesan, Devi, and Chakraborti, SutanuInternational Conference on Natural Language Processing (ICNLP) 2019Neural network based word embeddings, such as Word2Vec and GloVe, are purely data driven in that they capture the distributional information about words from the training corpus. Past works have attempted to improve these embeddings by incorporating semantic knowledge from lexical resources like WordNet. Some techniques like retrofitting modify word embeddings in the post-processing stage while some others use a joint learning approach by modifying the objective function of neural networks. In this paper, we discuss two novel approaches for incorporating semantic knowledge into word embeddings. In the first approach, we take advantage of Levy et al’s work which showed that using SVD based methods on co-occurrence matrix provide similar performance to neural network based embeddings. We propose a ’sprinkling’ technique to add semantic relations to the co-occurrence matrix directly before factorization. In the second approach, WordNet similarity scores are used to improve the retrofitting method. We evaluate the proposed methods in both intrinsic and extrinsic tasks and observe significant improvements over the baselines in many of the datasets.
@article{srinivasan2019integrating, abbr = {integrating19}, title = {Integrating Lexical Knowledge in Word Embeddings using Sprinkling and Retrofitting}, author = {Srinivasan, Aakash and Kamarthi, Harshavardhan and Ganesan, Devi and Chakraborti, Sutanu}, journal = {International Conference on Natural Language Processing (ICNLP)}, year = {2019}, bibtex_show = {true}, pdf = {https://arxiv.org/pdf/1912.06889}, selected = {true} }